Case Study 02: Predicting Annual Air Pollution
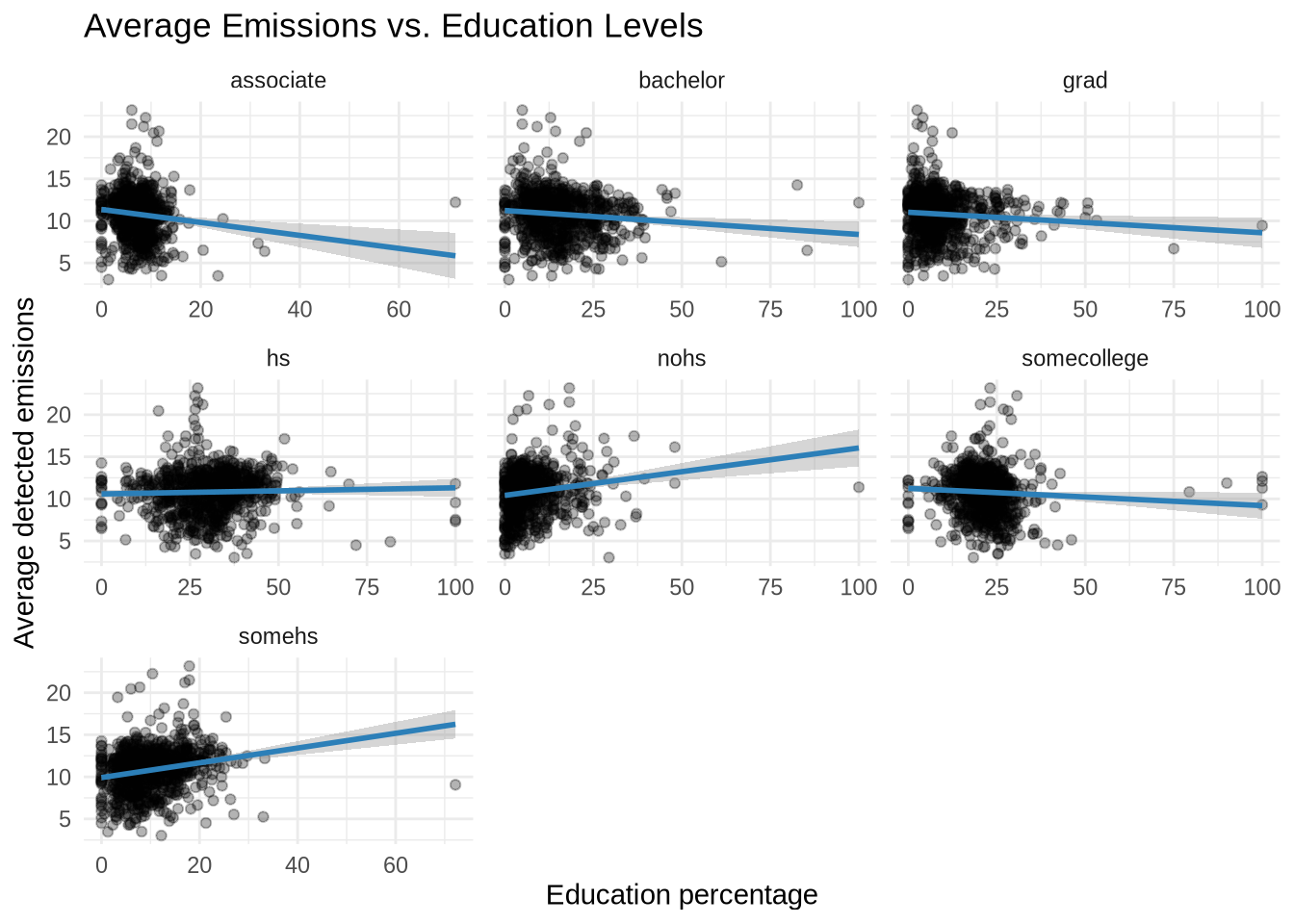
Conducted an in-depth analysis of air pollution patterns across the United States using advanced machine learning techniques in R and RStudio. Drawing on comprehensive data from the EPA's nationwide pollution monitoring network, our group developed a sophisticated predictive model that examines the complex interplay of environmental and socioeconomic factors influencing air quality. By leveraging packages like tidyverse, ggplot2, and tidymodels, we employed linear regression modeling to investigate how characteristics such as road lengths, zip code demographics, education status, and poverty levels correlate with local pollution levels. Our study meticulously mapped and analyzed pollution concentrations. Through rigorous statistical analysis and tidymodels machine learning algorithms, we generated insights that illuminate the multifaceted nature of air pollution distribution and its relationship to community characteristics.
Report is accessible here.